
生成AIによってデータ分析は民主化するか
―2つのユースケースから考えるデータ分析における生成AI活用のポイント―
はじめに
2023年にChatGPTが急速に普及したため、誰もが生成AIを身近に利用するようになり始めた。現在では、様々な企業がビジネスへの生成AIの活用に向けた探索・実証を着々と進めている。生成AIの活用領域は、情報抽出、翻訳、文章生成、等の多岐に渡る。中でも、OpenAI社のCode Interpreter(現Advanced Data Analysis)はデータ分析への生成AIの活用の可能性を示した。我々は、クライアント企業が抱える課題に対して、生成AIを活用してデータ分析から示唆を導出するまでの一連のプロセスの型化に向けて日々取り組んでいる。本稿では2つのユースケースをもとに、データ分析における生成AI活用のポイントをまとめる。
生成AIを活用したデータ分析の概要
本題に入る前に、まずは生成AIを用いたデータ分析の概要について述べる。生成AIを活用したデータ分析の仕組みは複数あるが、いずれも分析用プログラムのコード生成部分と、分析結果を解釈しユーザーが入力したプロンプトに回答する文章生成部分の2つのモジュールで構成される。
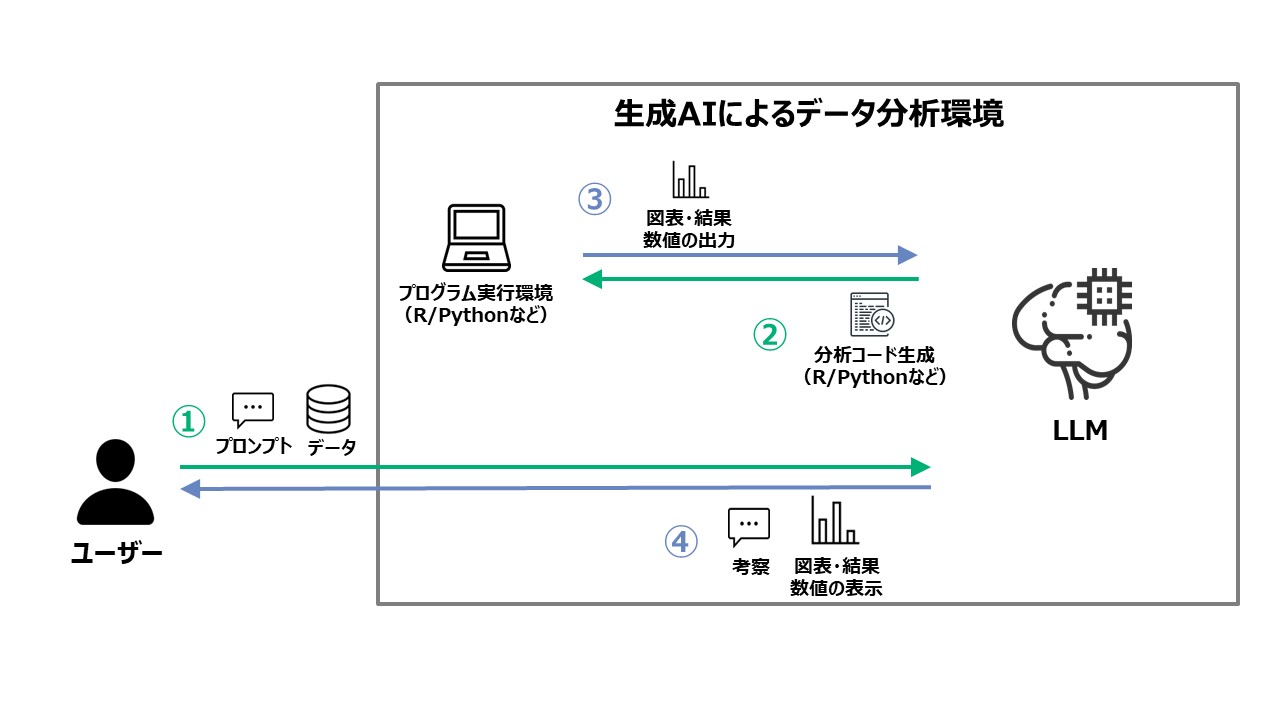
コード生成部分では、ユーザーが分析を行いたいデータを指定してプロンプトで指示する(図1 ①)と、LLM(大規模言語モデル)がその指示を遂行するための分析用のプログラミングコードを生成する(図1 ②)。続いて、生成したプログラミングコードを実際のプログラム実行環境で分析した後、結果として得られた図表や数値をインプットとして(図1 ③)、ユーザーが指示していたプロンプトの回答となるような結果をUI上に生成する(図1 ④)。図表や数値をインプットとする際は、実際に出力された図表を画像的に処理して理解するのではなく、プログラム実行環境の数値的な出力結果をテキストとしてインプットして生成するツールが主流となっている。
従来のプログラムコード生成・実行を行わない対話のみの生成AIでは、図1の②、③の工程は実現できなかった。しかし、図1の②、③が実装されたことによって生成AIはデータに基づいた示唆を導出するための強力なツールとなっている。
図1. 生成AIを用いたデータ分析ツールの概要
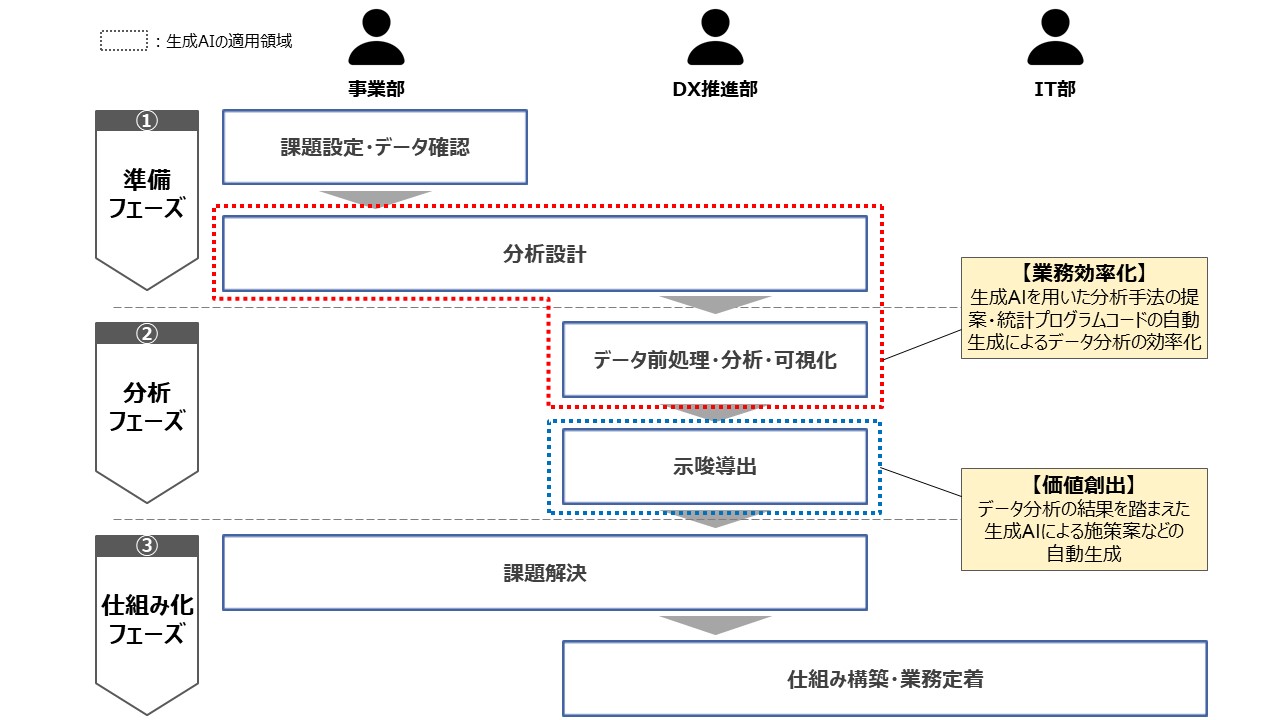
次に、ビジネスシーンにおいてデータ分析を行う際の一連の手続きを整理した上で、現状の生成AIの適用領域を示す。一連のデータ分析のプロセスを分解すると、「準備フェーズ」、「分析フェーズ」、「仕組み化フェーズ」の3フェーズに大別できる(図2)。体制面で考えると、3フェーズを1部門がすべて担う、もしくは各フェーズをそれぞれの部門が主管し複数部門で推進する場合がある。本稿の図2では、後者のケースを想定して記載している。
データ分析プロセスにおける生成AIの適用領域は、「分析設計」と「データ前処理・分析・可視化」という作業の業務効率化と、データ分析の結果をもとにした「示唆導出」という作業の価値創出の2点が挙げられる。業務効率化の観点では、分析手法の提案、プログラムコードの生成、適切なグラフの選択と生成、分析プログラム細部の修正など、生成AIによる一連のデータ分析の効率化が期待される。他方、価値創造の観点では、分析結果を踏まえた施策初期案の作成、結果の網羅的なパターン出しなど、生成AIによる従来人間が膨大な時間をかけて行っていた作業の高速化や価値向上が期待される。
以降では、我々が生成AIによるデータ分析の業務効率化と価値創造の2点を検証した「デジタルマーケティング領域での生成AIの活用」と「自治体業務における生成AIの活用」の2つのユースケースについて触れたいと思う。
図2. 一般的なデータ分析における生成AIの適用領域
ユースケース①:デジタルマーケティング領域での生成AIの活用
まず、デジタルマーケティング領域のユースケースを紹介する。属性情報、購買データなどの顧客データを用いたデータ分析を行う際、適切な洞察を得て顧客理解を深めるためには、データサイエンティストのようなデータ分析の専門性を有する人材が必要となる。さらに、一連のデータ分析のサイクルを完遂させるためには、一般に数か月単位の長い時間がかかることが大きな課題となっている。我々は、従来データサイエンティストが実施していた顧客理解のためのデータ分析作業の生成AIによる一部代替と、データ分析の示唆をもとに生成AIを用いてスピーディーかつ多様なデジタルマーケティング施策を導出することの2点に取り組んだ。
結果として、属性情報、購買データをインプットにしたところ、顧客理解のためによく用いられるRFM分析やクラスタリング、ペルソナ作成、カスタマージャーニー作成といったデータ分析を人間のコーディングなしで完遂させることができた。特に、具体的な分析内容を指定せずとも生成AI側でRFM分析を提案・実行できたことは分析設計部分への生成AI適用に向けた1つの示唆といえる。一方で、一度分析した結果を精密に検証すると生成によってアプローチが少しずつ異なる問題(再現性が低い)が明らかとなった。
また、顧客分析の結果を踏まえてデジタルマーケティング施策を生成したところ、玉石混淆ではあるものの叩き台として一定の網羅感・妥当性のある案が導出された。注意点として、コード生成・データ分析機能をもたない従来の生成AIにおいても網羅的な施策の導出は実証されている。今回は特に、データ分析の結果として生み出されたペルソナ、カスタマージャーニーをインプットに施策案を生成した。この点はデータ分析工程を経る強みと言える。一方で大量に生成した施策案については、実現可能性面で人間による精査が求められる点は従来の生成AIと同様であった。
ユースケース②:自治体業務での生成AIの活用
次に、自治体業務でのユースケースである。自治体業務は多岐に渡るが、特に総合計画策定や個別事業の評価といった場面において、データに基づいて意思決定を行う取り組みは多くの自治体で実施されている。しかし、定常業務に圧迫されデータドリブンでのPDCAサイクルが回せないこともまた、多くの自治体で共通の課題となっている。そこで、これまで自治体職員や外部委託者が担わなければならなかったデータ分析作業を生成AIによって一部代替して、業務効率化や価値創出に資するかを検証した。具体的には、自治体が保有している特定エリアの人流データ、車流データを時系列でみたときに、“どこに特異点があり”、“その背景に何があったか”、“それを踏まえて今後どのような施策案が考えられるか”、について生成AIを活用して分析した。
結果として、生成AIは独自に人流の過多・過少を判定する閾値を設定して特異な人流・車流があった日時を割り出し、その背景として天候とイベントが影響していたことを特定することで、人流を増やして車流を抑えるための施策案を導出した。興味深いことに、生成AIが導出した施策案は既に自治体で実施されているものが多く含まれていた。もちろん、生成AIが学習の過程でこれまで様々な自治体で実施された施策を学習している可能性がある点には留意する必要がある。それを踏まえても、自治体が時間をかけて考えた施策に対して、生成AI側はデータ分析によるエビデンスをもとに効率的かつスピーディーに施策案のベースを導出した点は評価に値する。
一方で、欠点として浮かび上がった点が大きく2点ある。ひとつは“数値的な特異点の背景に何があったか”を考える際には人間が仮説を考えて適切なデータを追加する必要があることである。2つ目は、一般論になりがちな施策案をブラッシュアップするために人間が根気強く壁打ち相手になる必要がある点だ。これらを踏まえると、現状ではデータ分析全ての工程を生成AIのみで完結させるのは難しい。
生成AIを活用するためのポイント整理
前述の2つのユースケースを踏まえて、生成AIを活用するためのポイントを「課題設定・データ確認」、「分析設計」、「データ前処理・分析・可視化」、「示唆導出」の4つの工程ごとに整理した(図3)。
図3. データ分析における生成AI活用のポイント
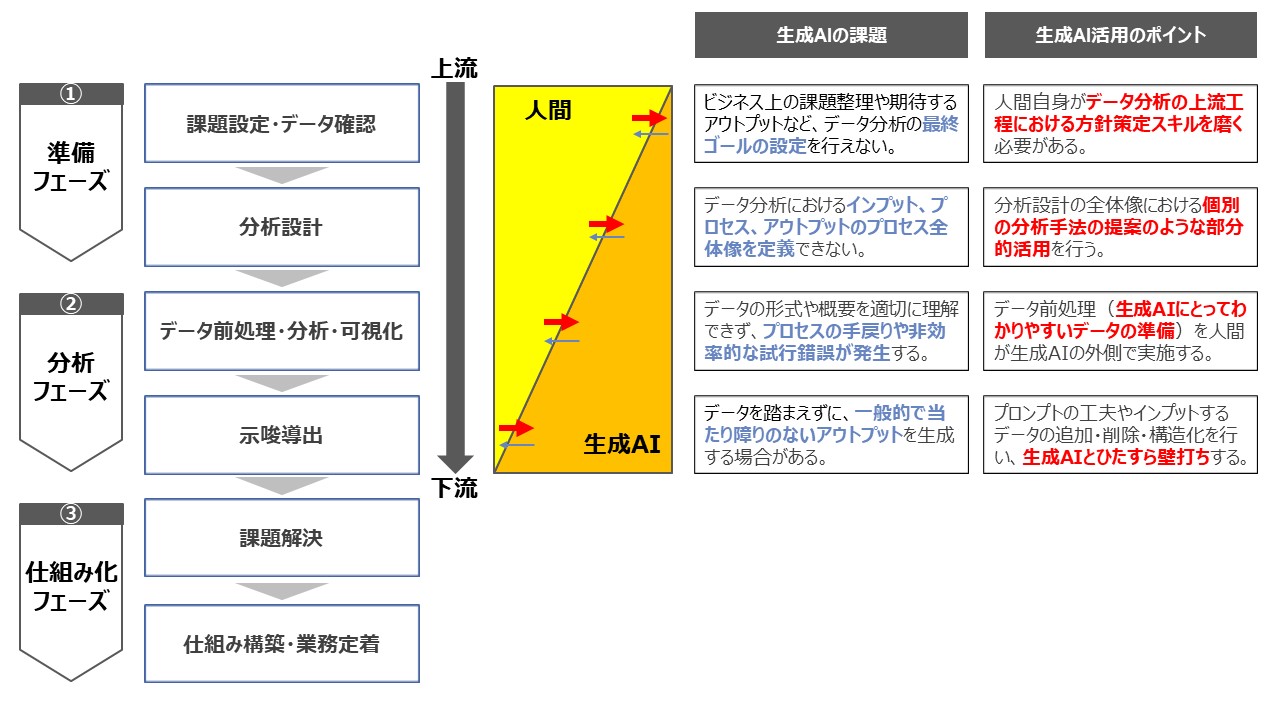
まずは、「課題設定・データ確認」のポイントである。一般的なデータ分析においても、ビジネス上の課題整理や期待するアウトプットの明確化は非常に重要である。一方で、生成AIがこの領域を完全に担えるかといえば、現時点では期待できないというのが我々の見解である。したがって、生成AIを活用したデータ分析を行う場合には、人間自身が当該領域の方針策定を担うためのスキルを磨く必要がある。
次に、「分析設計」では、どのデータをインプットにして、どのような処理を行い、どんな結果を導きたいかを設計する必要がある。こちらも現時点で生成AIにその役割すべてを担わせることは難しいが、部分的な活用は可能である。例えば、消費者分析を行う際のRFM分析やk-meansによるクラスタリングなど、統計分析手法は生成AIの提案する選択肢を参考にすることができる。統計的な専門知識が十分でない場合でも、どのような分析手法を採用すべきか、セオリーを教えてくれるツールとして有用だ。
「データ前処理・分析・可視化」については、コードを生成・実行するプロセスと定義した。定型化された統計処理であればともかく、データ分析プロジェクトの多くは、試行錯誤しながらデータ分析を推し進めていくという形になることが多い。その場合、生成AIを活用すると逆に非効率になることが我々の取り組みでわかってきた。試行錯誤のたびにデータの前処理やコーディングを1から生成することがその理由だ。これを解消するためには、「生成AIにとってわかりやすい」データを人間が前もって整備することが求められる。仮に生成AIに前処理部分を完全に任せると、コーディングミスやハルシネーションの確認で膨大な時間が割かれてしまう。そのため、データ前処理は生成AIに担わせるのではなく、むしろ生成AIの外側で人間が主となって実施することを推奨する。
最後に「示唆導出」については、生成AIのアウトプットが一般的で当たり障りのない内容になってしまうことへの対応がポイントとなる。基本的な対応方針としては、プロンプトに入力する文章やインプットするデータの追加・削除・構造化の実施である。プロンプトエンジニアリングと呼ばれるプロンプトでの試行錯誤の手法や、RAG(Retrieval Augmented Generation)と呼ばれる技術的なプロセスを実装する場合もある。データ分析に生成AIを適用する際によく使われるプロンプトエンジニアリングの例としては、思考連鎖型プロンプティング:CoT(Chain-of-Thought Prompting)などがある。Wei et al.(2023)が「Chain-of-Thought Prompting Elicits Reasoning in Large Language Models」の中で提唱した、一度にすべてを生成させるのではなく、ステップごとに分割して一つ一つを単純化して精度向上を狙う手法だ。先述の通り、生成AIによるデータ分析は自然言語だけでなくプログラミング言語も加えて生成する性質上、インプットもアウトプットも長くなる傾向にある。CoT(分析結果のサマライズ・分析プロセスの分割)は、回答の精度を上げるテクニックとして相性が良い。とはいえ、プロンプトやRAGはデータ分析の遂行のためのテクニックとしての位置づけとなる。本質的には、生成したい個別事例に関連したデータをいかに集めるのか、行いたい生成に対してのインプット形式の検討が求められる。この工程では辛抱強く生成AIと壁打ちを行うことが重要なポイントとなる。
以上を俯瞰的な視点でまとめると、現時点では生成AIの登場によってデータ分析が完全に民主化されたわけではなく、データ分析の上流から下流にかけて生成AIの役割は大きくなっていくものの、人間が担わなければならない作業は依然多いと言える。生成AIの課題をよく理解したうえで、データ分析のプロセス全体は人間がリードするような姿が理想であると考える。社会人になりたての優秀でタフなデータサイエンティストがあなたのすぐ隣にいるシーンを想像してみてほしい、その新人(=生成AI)をうまくリードできるスキルが今後は重要になってくるのではないだろうか。
おわりに
本稿では2つのユースケースから生成AIのデータ分析への適用におけるポイントについて考察を行った。生成AIのビジネス活用の黎明期にある今、データ分析の成果を最大化するためにはLLMおよび周辺環境の技術的な性能向上だけでなく、人間自身が課題整理、全体設計、仮説構築、検証といったスキルを磨いていかなければならない。そういう意味では、生成AIは人間が担わなければならないデータ分析のスキルを磨いていくうえでの良い研修コンテンツとも言えるかもしれない。完全な民主化への道のりはまだ遠いが、生成AIを活用したデータ分析の民主化の動向を引き続き注視していきたい。