人工知能技術のユニバーサルサービス化に向けて(上)
-ハードウエアとソフトウエアから見るAI技術環境-
デジタルコグニティブサイエンスセンター
R&Dグループ
コンサルタント 稲村 博央
はじめに
人工知能(以下AI)という言葉はバズワードを通り越し、日常的にビジネスの中で使われる用語となりつつある。昨今、AIに関する技術やサービスの話題は尽きず、情報通信分野などの特定の分野だけではなく、エネルギー、金融、医療、消費サービス、インフラサービスなど、あらゆる分野でAIが活用されはじめ、気付かないうちに私たちの日常生活にも入り込んでいる。
囲碁のプロ棋士に勝利を収めたことで有名なGoogle DeepMind社はそのAI技術を使い、自社データセンターの冷却電力などを40%削減したと発表した※1。Googleのデータセンターは電力コストを10%削減できるだけでも数年間で数億ドルのコスト削減になると言われているため、その効果の大きさには目を見張るものがある。また、東京大学医科学研究所は特殊な白血病患者の病状をIBM Watson※2で分析し、10分で原因となる部分を特定、治療方法を変えたところ患者の容体が回復に向かったという。この記事が各種マスコミを賑(にぎ)わせたのは記憶に新しい※3。
今後、AIはどう進化していくのか。現在のAIブームの先にあるものは何か。筆者は以下の2点を「AI技術のユニバーサルサービス化」と定義し、AI技術のトレンドと展望を解説する。
- (1)高度な専門性を持たずとも、AI技術の導入ができる環境とサービス
- (2)幅広く日常生活のさまざまな分野にAI技術が取り入れられ、AIサービスがコモディティ化している状態
- ※1 DeepMind AI reduces energy used for cooling Google data centers by 40%.(https://green.googleblog.com/2016/07/deepmind-ai-reduces-energy-used-for.html)
- ※2 IBMはIBM Watsonを「コグニティブ・コンピューティング・システム」と定義している。
- ※3 東大の人工知能「ワトソン」、10分で遺伝子解析…白血病患者を救う。(https://yomidr.yomiuri.co.jp/article/20160806-OYTET50000/)
ハードウエアの発展から見るAIブーム
昨今のAIブームに対し、マスコミを通じた「GoogleのAIが猫を認識」や「AlphaGoがプロの囲碁棋士に初勝利」、「Microsoftの女子高生AIりんなちゃんデビュー」といったキャッチーな内容・話題性の喚起による部分が大きく影響していることは無視できない。
しかし、そのブームの背景を技術的な視点から見ると、そこにはハードウエアとソフトウエアの大きな発展と激しい競争が背景にある。
ハードウエアの視点からみると、まず、2000年初頭に比べ、現在では膨大なストレージ容量を低コストで利用することが可能となっている。例えば、2000年頃はHDDのストレージ容量は1GB/10$ほどであったが、2016年には1GB/0.01$ほどにまで低下している。より高速なデータアクセスを可能とするSSDについても、SanDisk社は2017年にはHDDと変わらない単価になると予測している※4。これはSSDが登場した2010年の1/10以下のコストである(図表1)。
図表1:ストレージ価格の変遷と2017年の予測価格
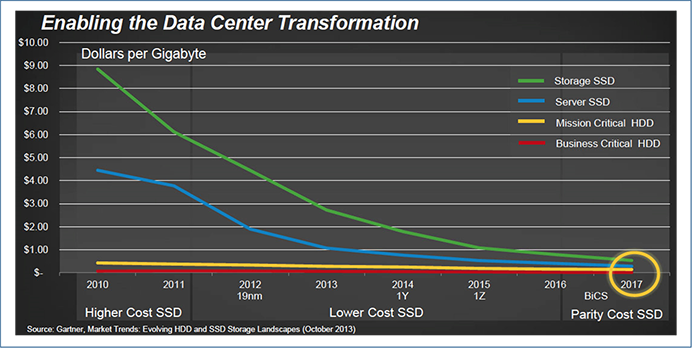
(出所)SanDisk plans to release 6TB and 8TB SSDs in 2016
(http://www.kitguru.net/components/ssd-drives/anton-shilov/sandisk-is-developing-6tb-8tb-ssds-for-datacentres-plans-to-introduce-them-in-2016/)
また、プロセッサの処理性能・速度も2000年代初頭に比べ、大きく発展しており(図表2)、分散処理環境のコモディティ化も進んでいる。
図表2:CPUベンチマークスコアの遷移
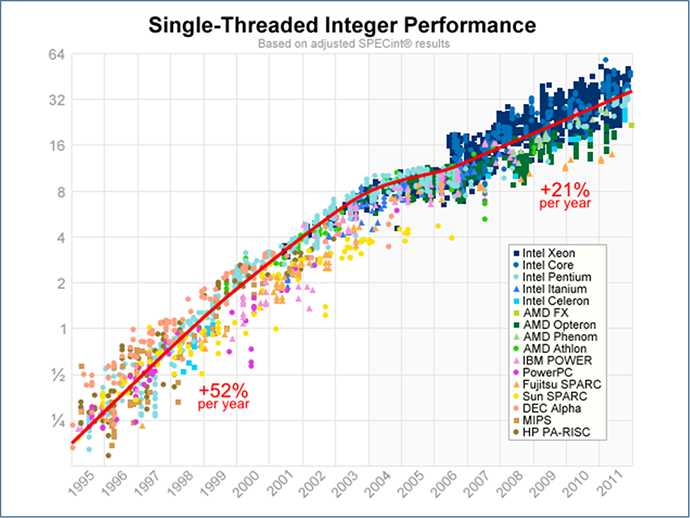
(出所)A Look Back at Single-Threaded CPU Performance
(http://preshing.com/20120208/a-look-back-at-single-threaded-cpu-performance/)
そのため、廉価なクラウドサービス※5が登場し、ストレージ面では無限に近いスケーラビリティを獲得し、処理性能面でもコンピュータリソースを必要な時に、必要なだけ調達することが可能となった。
この発展は、構造型データ※6・非構造型データ※7を合わせ、膨大な量のデータ利用を可能とした。
言い換えれば、
- (1)AIの研究開発・精度向上には「AIが学習するための膨大なデータ」が必要
- (2)膨大な学習データから「AIが学習するための計算能力(計算環境)」が必要
という二つの大きな課題について、無限に近いストレージを廉価に扱えるようになったことで(1)の技術的課題を解決し、プロセッサや分散処理環境の発展によって(2)の技術的課題を解決したということだ。
特に、現在のAIブームの中核を担っているディープラーニング(深層学習)※8は大量のデータだけでなく、莫大(ばくだい)な計算能力を必要とする。そこで、ディープラーニングではCPUだけではなく、GPGPU(General Purpose computing on Graphics Processing Units)と呼ばれるGPUを用いた計算処理が必須となっている。
そのため、GPU大手のNVIDIAは機械学習への利用を前提としたGPUを続々と開発しており、2016年7月には「NVIDIA TITAN X」、9月にはディープラーニング向け数値演算アクセラレータ「Tesla P40」「Tesla P4」を発表した※9。
また、CPU大手のIntelも同じく2016年6月にXeon Phiを機械学習向けに最適化することを発表し、GPU陣営に対抗している※10。
Googleに至っては2016年5月にTensor Processing Unit(TPU)と呼ばれるディープラーニング専用プロセッサを独自開発し、すでに一部環境下で使用していることを発表した※11。このGoogleの開発したTPUは従来のGPUに比べ、消費電力あたり10倍の性能を発揮しているとのことだ。
ハードウエア分野の競争は、AIを開発する側から見ると、開発環境コストの低減が期待できる。例えば、AI開発環境をオンプレミス(自社運用)で構築せずとも、必要に応じクラウド上で速やか、かつ柔軟に利用できるようになる。
実際、ホスティング・クラウドサービスを展開するさくらインターネット社は、2016年8月に機械学習で必要な計算資源を「高火力コンピューティング」と位置付け、機械学習向けGPUサービスの提供を開始した※12。Amazonも2016年10月にP2インスタンスという最大で16個のGPUからなる機械学習・ゲノム解析・金融工学などに向けたプランの提供を発表した※13。
このような環境はKaggle※14という世界的なデータ解析コンペティションにも影響を与えている。Kaggle参加者は性能差の大小はあれ、個人レベルで1990年代のスパコン以上の性能を持つGPU環境を自前で構築、あるいはクラウド上の豊富なリソースを活用して実現している。そのため、Kaggleではディープラーニングをはじめとする機械学習による予測やモデル構築に参加者が日々チャレンジし、大きな成果を出している。このように、AI開発環境のハードルは大きく下がりつつある。
- ※4 SanDisk plans to release 6TB and 8TB SSDs in 2016.(http://www.kitguru.net/components/ssd-drives/anton-shilov/sandisk-is-developing-6tb-8tb-ssds-for-datacentres-plans-to-introduce-them-in-2016/)
- ※5 代表的な商用サービスとしてAmazon Web Service、Microsoft Azure、Google Cloudがある。
- ※6 POSデータや名簿データ等のRDBMSによる完全構造を持つデータ。
- ※7 画像、音声、動画、SNSの投稿等の完全構造を持たないデータ。
- ※8 多層構造のニューラルネットワークを用いた機械学習の手法であり、現在のAIブームの中核技術となっている。
- ※9 New Pascal GPUs Accelerate Inference in the Data Center.(https://devblogs.nvidia.com/parallelforall/new-pascal-gpus-accelerate-inference-in-the-data-center/)
- ※10 Intel tunes its mega-chip for machine learning.(http://www.pcworld.com/article/3091028/intel-tunes-its-mega-chip-for-machine-learning.html)
- ※11 Google supercharges machine learning tasks with TPU custom chip.(https://cloudplatform.googleblog.com/2016/05/Google-supercharges-machine-learning-tasks-with-custom-chip.html)
- ※12 さくらインターネット、高火力コンピューティングの機械学習向けGPUサービスを提供開始。(https://www.sakura.ad.jp/press/2016/0831_koukaryoku/)
- ※13 Amazon's new GPU-cloud wants to chew through your AI and big data projects.(http://www.zdnet.com/article/amazons-new-gpu-cloud-wants-to-chew-through-your-ai-and-big-data-projects/)
- ※14 企業や研究者がデータを提供し、参加者がモデル化や精度を競いあう、世界的なデータ解析コンペティションおよびプラットフォームのこと。優秀な予測モデルや精度改善を達成した参加者には賞金が授与される。(https://www.kaggle.com/)
ソフトウエアの発展から見るAIブーム
ハードウエア的には高度なコンピューティング環境が実現された現在であるが、AI技術はソフトウエア分野においても進化が続いている。
ディープラーニングをはじめとする機械学習技術を独自に実装しようとした場合、高度な数学的知識、プログラミング知識およびハードウエア知識を求められることとなり、そのハードルは非常に高かった。しかし、さまざまな企業・コミュニティで開発・提供されているOSS※15のディープラーニングフレームワークや機械学習フレームワークを用いることで、そのハードルを大きく下げることができるようになった。
有名なものは2015年11月にGoogleが公開した「TensorFlow」※16だ。これは韓国のプロ棋士イ・セドルを破ったAlphaGoやGoogle Cloud Vision API※17でも利用されている。また、日本発のディープラーニングフレームワークとしてPreferred InfrastructureおよびPreferred Networksが開発し、提供する「Chainer」※18がある。以下に代表的なディープラーニングフレームワークをいくつか提示する(図表3)。
図表3:代表的なディープラーニングフレームワーク
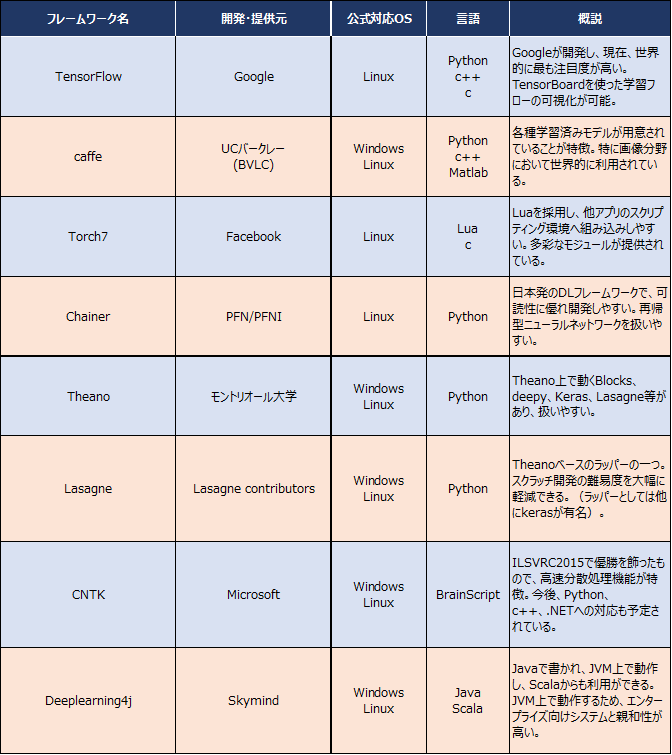
(出所)浅川伸一著「Pythonで体験する深層学習」および各フレームワークドキュメントを参考にNTTデータ経営研究所にて作成
このように、次々と新しいディープラーニングフレームワークが提供され出しており、誰もがそれぞれのオープンソースライセンスに基づいて利用することが可能となっている。
中でも特に注目されているのはGoogleが公開したTensorFlowだろう。2016年9月末時点で、TensorFlowはGitHub※19で30,000を超えるStar※20と14,000を超えるFork※21となっている。一方で、Microsoftの公開したCNTKはILSVRC2015※22で優勝しているが、元々は、Microsoft社内で有志により開発され、対外的にはアカデミックライセンスに限定されていたものだ。これをMITライセンス※23に切り替え2016年1月に公開した背景には、2015年11月にGoogleがTensorFlowをOSS化したことが大きく影響しているだろう。
MicrosoftがOSSコミュニティモデルを利用することは、AI技術分野全体の発展に寄与するだけでなく、Microsoftの存在感をアピールすることになる。GoogleやFacebookだけでなく、Microsoftもその技術をOSSコミュニティモデルとしたことは、それだけAI技術分野が重要であることの裏返しでもある。AI技術に関するソフトウエア分野の発展は今後もさらに加速して行くだろう。
- ※15 オープンソースソフトウエアの略。
- ※16 TensorFlow.(https://www.tensorflow.org/)
- ※17 Google Cloud Platform CLOUD VISION API.(https://cloud.google.com/vision/)
- ※18 Chainer: A flexible framework of neural networks.(http://chainer.org/)
- ※19 バージョン管理ソフトGitを用いた、ソフトウエアコードの共有ウェブサービス。GoogleやMicrosoft等の大手企業から個人まで多くのアカウントでソースコードが公開されている。(https://github.com/)
- ※20 利用ユーザによる「いいね」や「お気に入り」とほぼ同じ意味を持つ。
- ※21 分散バージョン管理システムGitを用いたGithubの機能で、一つのプロジェクトリポジトリを他ユーザが自身のリポジトリにコピーし、オリジナルに対する書き込み権限が無くとも自身のリポジトリ内でコピー・改変することができる機能。このようにオリジナルリポジトリから枝別れしていくものをフォークに見立てForkと名付けられている。
- ※22 ImageNet Large Scale Visual Recognition Challengeという2010年から毎年開催されている大規模画像認識コンテスト。(http://www.image-net.org/challenges/LSVRC/)
- ※23 マサチューセッツ工科大学を起源とする代表的なソフトウエアライセンス。著作権表示・本許諾表示をソフトおよび複製または重要な部分に記載することで、誰でも無償で無制限に扱って良い。
おわりに
本稿では、AIブームの背景をハードウエア・ソフトウエアの観点から解説した。企業・ユーザを問わず、AI技術を扱えるエンジニアやコンサルタントは増えているものの、現状では圧倒的に人材不足である。
AIの開発は環境面でのハードルが下がっているとはいえ、依然としてAI技術の開発・導入には一定以上の知識とスキルが求められる。本稿で述べたようなOSSのフレームワークやクラウド環境があるからといって、ほとんど知識を持たない者がすぐにAI技術を導入・利用できるかというと、やはり非常に難しい。
そのため、現在もデータサイエンス・AI分野の人材は売り手市場で獲得合戦となっている。国内外問わず、大手企業によるAI技術スタートアップ企業への出資、提携、買収のニュースが多いことからも読み取れる。
続く次稿「人工知能技術のユニバーサルサービス化に向けて(下)-クラウドAIサービスで広がるAI技術-」では、データサイエンス・AI分野が人材獲得合戦になっている背景と、次々に登場するクラウドAIサービスと合わせ、AI技術のユニバーサルサービス化について展望を考察して行く。